一、 简介
Buffer是一个写入通道或者从通道中读取的数据块。Buffer是Java I/O和Java NIO的主要差异之一。对于早期的Java I/O,数据是基于流的方式进行读写的,而现在NIO是基于buffer的方式来读写的。NIO中的通道跟流是一个意思。
二、 Buffer特性
- Buffer是Java NIO的基本构成组件。
- Buffer提供了一个固定大小的容器来读写数据。
- 每个buffer都是可读的,但是只有被选中的buffer才是可写的。
- Buffer是通道的端点。
- 在一个只读buffer中,内容是不可变的,但是它的 mark, position, limit 是可变的。
- 默认的buffer是线程不安全的
Buffer的读写模式如图所示:
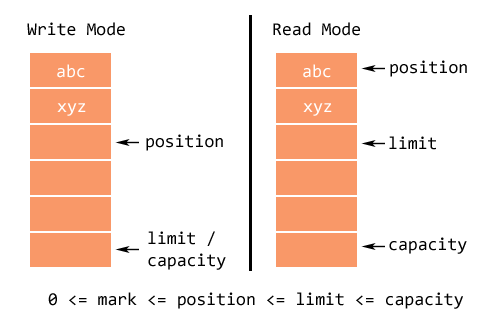
三、 Buffer的类型
每个基本类型都有一个buffer类型想对应。所有的buffer类都实现了 Buffer 接口。大部分使用的类型是 ByteBuffer。下面是在Java NIO包中可用的buffer类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- MappedByteBuffer
如图所示:
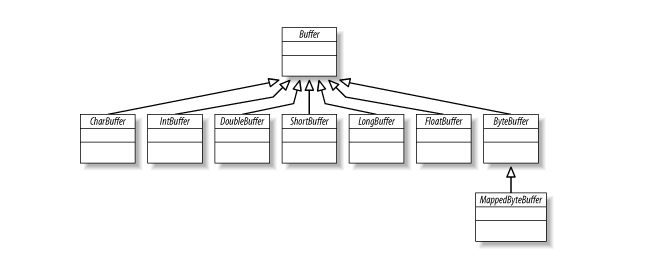
这些类都不能直接实例化,因为他们都是抽象类,但是每个都包含了静态工厂方法来创建适当类的实例。
四、 Buffer的基本属性
Buffer有四个基本的属性,下面简单介绍下
1、容量Capacity
Buffer是一个固定大小的类型,这个最大固定大小就叫做capacity。一旦这个buffer是满了,那么就应该在写入它之前清空它。一旦capacity被设置,在它的生命周期内就不能再被改变了。
2、上界Limit
对于写模式,limit 是等于buffer的 capacity的。对于读模式,limit是buffer的最后填充索引的下一个。当buffer被写入时,limit会自增。limit满足下面的条件: 0 <= limit <= capacity
3、位置Position
Position是buffer中下一个要被读或者写的元素的索引。当buffer被创建时,position被初始化为0。当读写时,position是自增的。position总是处于0和limit之间。
4、标记Mark
Mark就像是buffer中为position设置的书签一样。调用 mark() 来设定 mark = position,调用 reset() 来设定 position = mark 。
五、 Buffer相关操作
1、flip()
该方法被用来为 get() 操作准备一个 buffer ,或者是用来准备一个新的写序列。flip() 方法设置 limit 等于buffer的当前 position,然后将 position = 0。
2、clear()
该方法用来为 put() 操作准备一个 buffer,或者用来准备一个新的读序列。clear() 方法设置 limit = capacity 和 position = 0。
3、rewind()
该方法用来再次读取数据。它设置 position = 0。
六、 Buffer的创建
Buffer是通过 allocation 或者 wrapping 来创建的。allocation 创建一个buffer对象,并且分配指定容量的私有空间来容纳数据元素。wrapping 创建一个buffer对象,但是不分配任何的空间来保存数据元素,它使用你提供的数组空间来存储buffer的数据元素。
举例,创建一个能够容纳100个字符的 CharBuffer:
上面这种方式,隐式的从堆上分配了一个char数组来存储这100个字符。如果你想要使用你自己创建的数组来存储,则使用 wrap() 方法:
这意味着通过调用 put() 方法对buffer做的变更都会反映到这个数组中。同样的,对这个数组做的任何改变都将反映到buffer中。
你也能够通过指定偏移和长度值作为 position 和 limit 来构造buffer:
注:
- 这个方法不会创建一个buffer,而是指向改数组的一个子集
- 这个方法拥有这个数组整体的访问权,偏移和长度参数仅仅只是设置初始状态。
- 调用这个buffer的
clear()方法将使它的limit范围变为这个数组的所有元素 - 调用
slice()方法能够创建一个buffer指向这个数组的一部分
通过 allocate() 或者 wrap() 方法创建的buffer都不是直接在内存中开辟空间的,而是指向一个已有的数组。使用 hasArray() 方法告诉你这个buffer是否有一个相关联的数组,如果返回 true,则可以使用 array() 方法返回一个数组的引用给buffer。如果返回 false,就不要调用 array() 和 arrayOffset(),否则将抛出 UnsupportedOperationException 异常。
七、访问Buffer
每个buffer类都提供了 get() 和 put() 方法来访问buffer,比如:
访问API有绝对和相对之分,调用相对访问API时,position 会自动的向前进一个,调用绝对访问API时,指定索引位置的内容会被覆盖掉或者按指定索引返回内容。
八、 Buffer的比较
所有的buffer类都提供了一个自定义的 equals() 方法 和 compareTo() 方法,比如:
两个buffer按照下面的规则进行比较:
- 包含的对象必须是同等类型的
- 两个buffer必须包含有相等数量的元素, 也就是说,buffer的容量不需要相同,buffer中剩余的数据索引不需要相同,但是buffer中剩余元素的数量(从
position到limit)必须相同 - 从
get()返回的剩余数据元素的序列在每个缓冲区中必须相同。
buffer还支持使用compareTo()方法进行词典比较。该方法返回一个正数、负数或者0。比如:
参考文章 Working With Buffers

